
While implementing a Sha256 hashing algorithm using Zig, I encountered the problem of converting a [64]u8 array to a [16]u32 array. For example:
//From b to s
var b = [4]u8 {0b1100001, 0b00100000, 0b01101101, 0b01100101};
var s = [1]u32{0b1100001_00100000_01101101_01100101};
After trying a few things, I came up with this solution (not the most elegant, but we'll see later how Zig achieves the same result):
fn cast(buffer: [64]u8, blocks: [16]u32) void {
var idx: usize = 0;
var idxBuff: usize = 0;
while (idx < 16) : (idx += 1) {
blocks[idx] = @as(u32, buffer[idxBuff]) << 24 | @as(u24, buffer[idxBuff + 1]) << 16 | @as(u16, buffer[idxBuff + 2]) << 8 | buffer[idxBuff + 3];
idxBuff += 4;
}
}
The first 8 bits buffer[idxBuff] are casted to 32 bits using the @as builtin function, and then shifted left (<<) 24 positions to fill with 0, moving the initial 8 bits from the right to the left.
initial value: `01100001`
u32 casted: `00000000 00000000 00000000 01100001`
24 left shifted: `01100001 00000000 00000000 00000000`
The same is done with the next 3 values, but changing the size and the number of shift left positions. The next value buffer[idxBuff + 1] becomes:
initial value: 00100000
u24 casted: 00000000_00000000_00100000
16 left shifted: 00100000_00000000_00000000
After that cast and shift, a bitwise OR operation is performed with the casted values. This OR operation combines the four values as follows:
1100001 00000000 00000000 00000000 |
00100000_00000000_00000000 |
01101101_00000000 |
00110010
Result:
1100001_00100000_01101101_01100101
Finally we end up with the desired value
0b1100001_00100000_01101101_01100101
How zig solve this?
check the code here
fn round(d: *Self, b: *const [64]u8) void {
var s: [64]u32 align(16) = undefined;
for (@as(*align(1) const [16]u32, @ptrCast(b)), 0..) |*elem, i| {
s[i] = mem.readIntBig(u32, mem.asBytes(elem));
}
...
...
}
Let’s break down each line and explain what it does:
var s: [64]u32 align(16) = undefined;
The first line declares an array of unsigned 32 bits with a 16 byte alignment. This ensures that the memory address used to store s is divisible by 16. Then the array is declared as undefined
Second line:
for (@as(*align(1) const [16]u32, @ptrCast(b)), 0..) |*elem, i|
The second line takes b (a pointer) and casts it using @ptrCast converting b to a pointer of *align(1) const [16]u32 to achieve this is needed to use the builtin function @as to coerce the type. In this case the pointer is aligned to 1 because b is aligned to 1.
The same result can be achieved by doing this:
var bp: *align(1) const [16]u32 = @ptrCast(b);
In this example the use of @as is not necessary because the type is declared along with the variable.
After casting b the result is iterated with a for loop that receives the casted pointer and an index.
Third line:
s[i] = mem.readIntBig(u32, mem.asBytes(elem));
At this point we already have a u32 value that can be stored in s array. So.. why we don’t store it just as it is?
Well it’s not that easy because the endianness comes into play. For example, consider this u8 array:
{0b1100001, 0b00100000, 0b01101101, 0b01100101}
is stored in memory like this:
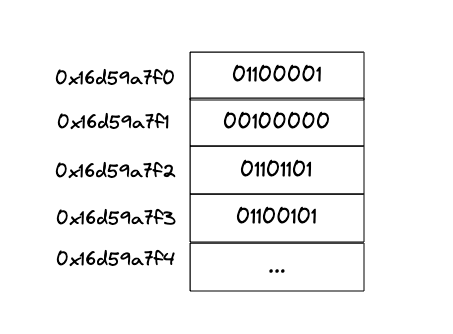
and if you have an architecture that uses little endian when you cast the u8 array to a u32 array the value will be read reversed, like this:
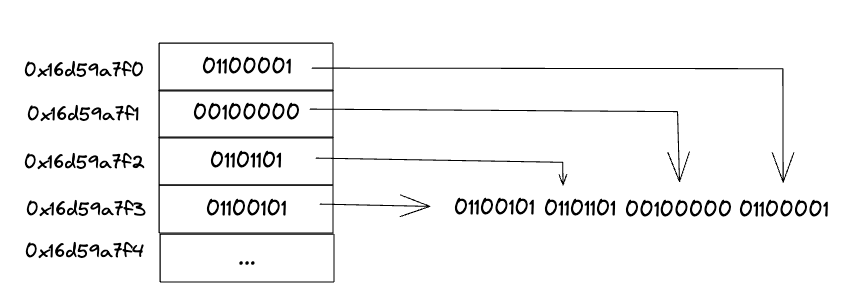
This is because when you cast the u8 pointer to u32 pointer the addresses remain in the same location, thus when the u32 value is read asumes that it was stored using little endian. But we want to keep the same order in this case.
So this third line achieve that:
s[i] = mem.readIntBig(u32, mem.asBytes(elem));
First of all, the u32 value 'elem' is passed to the 'asBytes' function from the standard library to retrieve a slice of the underlying bytes of 'elem'. As a result, we end up with the same u8 values in the same order before being casted. Then, this slice is passed to the 'readIntBig' function. This function reads the slice of u8 values using big endian and casts it to u32.
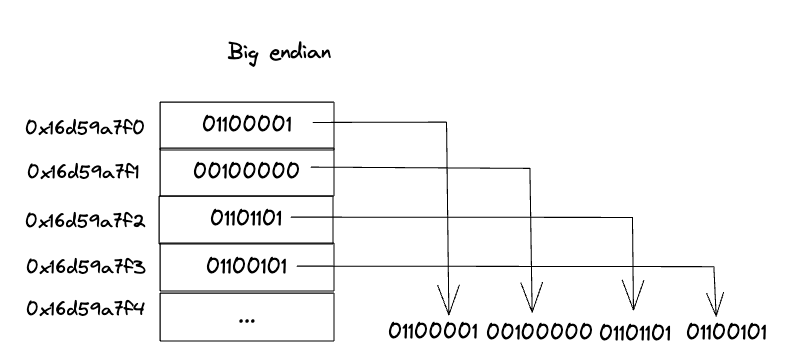
The result is stored in s array, and that's how Zig achieves this casting.





Oldest comments (0)