Intro
So I was recently wondering, what is going on with the hashes in build.zig.zon. They all have the same prefix, which is rather unusual for cryptographic hashes. Accustomed to Conda and Yocto, I tried running sha256sum on downloaded tarballs, but resulting digests were nowhere similar to hashes present in the build.zig.zon.
.dependencies = .{
.mach_freetype = .{
.url = "https://pkg.machengine.org/mach-freetype/309be0cf11a2f617d06ee5c5bb1a88d5197d8b46.tar.gz",
.hash = "1220fcebb0b1a4561f9d116182e30d0a91d2a556dad8564c8f425fd729556dedc7cf",
.lazy = true,
},
.font_assets = .{
.url = "https://github.com/hexops/font-assets/archive/7977df057e855140a207de49039114f1ab8e6c2d.tar.gz",
.hash = "12208106eef051bc730bac17c2d10f7e42ea63b579b919480fec86b7c75a620c75d4",
.lazy = true,
},
.mach_gpu_dawn = .{
.url = "https://pkg.machengine.org/mach-gpu-dawn/cce4d19945ca6102162b0cbbc546648edb38dc41.tar.gz",
.hash = "1220a6e3f4772fed665bb5b1792cf5cff8ac51af42a57ad8d276e394ae19f310a92e",
Snippet above is taken from the hexops/mach project.
First findings
After some digging, I found doc/build.zig.zon.md (and literally nothing points to it?). It has a short description of the hash field.
hash
String.
multihash
This is computed from the file contents of the directory of files that is obtained after fetching url and applying the inclusion rules given by paths.
This field is the source of truth; packages do not come from a url; they come from a hash. url is just one of many possible mirrors for how to obtain a package matching this hash.
multihash
We have our first clue - multihash. On their website there is a nice visualization of what is happening:
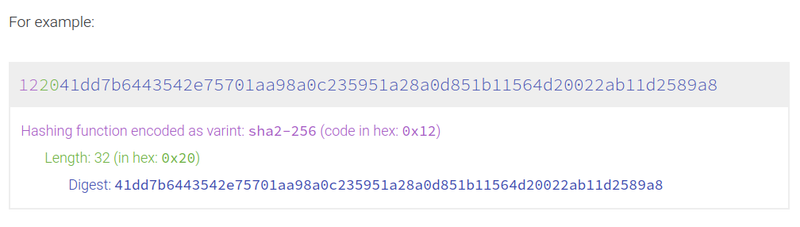
So the hash field in build.zig.zon not only contains the digest, but also some metadata. But even if we discard the header, we still don't get anything similar to sha256sum of the downloaded tarball. Well, that's where we get into inclusion rules.
Inclusion rules
Going back to the doc/build.zig.zon.md file, we see:
This is computed from the file contents of the directory of files that is obtained after fetching url and applying the inclusion rules given by paths.
What are those mysterious inclusion rules? Unfortunately, I again couldn't find any description of this stuff. The only place where it was mentioned was the beginning of the ziglang/src/Package/Fetch.zig file, but even there, the only thing we learn is that files that are excluded are being deleted, and the hash is being computed based on the remaining files.
Thankfully after a quick search through the code, we find main function of the fetch job, which is responsible for hash calculation.
It's not easy to find, but finally at the end we see it calling runResource function. There, paths field is being read from the build.zig.zon of the dependency and is being later used to create some kind of filter.
But wait. It's not just some filter. It's the filter we've been looking for. Inside this struct's namespace is defined function includePath, which seems to handle all those inclusion rules.
/// sub_path is relative to the package root.
pub fn includePath(self: Filter, sub_path: []const u8) bool {
if (self.include_paths.count() == 0) return true;
if (self.include_paths.contains("")) return true;
if (self.include_paths.contains(".")) return true;
if (self.include_paths.contains(sub_path)) return true;
// Check if any included paths are parent directories of sub_path.
var dirname = sub_path;
while (std.fs.path.dirname(dirname)) |next_dirname| {
if (self.include_paths.contains(next_dirname)) return true;
dirname = next_dirname;
}
return false;
}
This function tells whether a file at sub_path is part of the package. We can see that there are three special cases where a file is unconditionally assumed to be a part of the package:
-
include_pathsare empty -
include_pathshave an empty string"" -
include_pathshave package's root directory"."
Otherwise, this function checks if the sub_path is listed explicitly or is a child of directory that was explicitly listed.
Hash calculation
Ok, so we know what are those mysterious inclusion rules for build.zig.zon and we know that SHA256 algorithm is involved, but we still don't have a single clue how the actual hash is obtained. For example, it could be calculated by feeding a hasher with the content of all included files. So let's look a little bit more, and maybe we can find our answers.
Going back to runResource, we see that it calls computeHash function, which looks like the main thing that should interest us (unfortunately the comment at the top of it looks to be outdated as there is definitely file deletion going on inside).
Inside we stumble upon this snippet:
const hashed_file = try arena.create(HashedFile);
hashed_file.* = .{
.fs_path = fs_path,
.normalized_path = try normalizePathAlloc(arena, entry_pkg_path),
.kind = kind,
.hash = undefined, // to be populated by the worker
.failure = undefined, // to be populated by the worker
};
wait_group.start();
try thread_pool.spawn(workerHashFile, .{
root_dir, hashed_file, &wait_group,
});
try all_files.append(hashed_file);
We don't pass any hasher object, only the project's root directory and a pointer to the HashedFile structure. It has a dedicated field for hash. So it seems our little theory was immediately debunked, given hash value is being stored for individual files. To understand it better, let's follow this new trail and see what's going on.
Following workerHashFile, we see it's a simple wrapper over hashFileFallible, which in turn looks rather meaty. Let's break it down.
Hashing a single file
First we have some setup, where a new hasher instance is being created and initialized with normalized path of the file:
var buf: [8000]u8 = undefined;
var hasher = Manifest.Hash.init(.{});
hasher.update(hashed_file.normalized_path);
Then we switch over the type of file we are hashing. There are two branches: one for regular files and one for symlinks.
Let's look into regular file case first:
var file = try dir.openFile(hashed_file.fs_path, .{});
defer file.close();
// Hard-coded false executable bit: https://github.com/ziglang/zig/issues/17463
hasher.update(&.{ 0, 0 });
var file_header: FileHeader = .{};
while (true) {
const bytes_read = try file.read(&buf);
if (bytes_read == 0) break;
hasher.update(buf[0..bytes_read]);
file_header.update(buf[0..bytes_read]);
}
We open the file to read its content later, that's expected. But just after this we stuff put two null bytes. From reading linked issues it seems that it's related to a mostly historic thing that is preserved to not invalidate hashes that are in use. Anyway, later we simply loop over chunks of the file's data and feed the hasher with them.
Now onto the symlink branch, which is even simpler:
const link_name = try dir.readLink(hashed_file.fs_path, &buf);
if (fs.path.sep != canonical_sep) {
// Package hashes are intended to be consistent across
// platforms which means we must normalize path separators
// inside symlinks.
normalizePath(link_name);
}
hasher.update(link_name);
Here, we normalize the path separator character and feed the symlink's target path to the hasher.
At the end of hashFileFallible we store computed hash in the passed HashedFile object hasher.final(&hashed_file.hash);.
Combined hash
We have hashes of individual files, but we still don't know how to arrive to the final hash. Fortunately, not much is left to do.
Next step is to make sure we have reproducible results. HashedFile objects are stored in an array, but for example file system traversal algorithm might change, so we need to sort that array.
std.mem.sortUnstable(*HashedFile, all_files.items, {}, HashedFile.lessThan);
Finally, we arrive to the part where all those hashes are combined into one:
var hasher = Manifest.Hash.init(.{});
var any_failures = false;
for (all_files.items) |hashed_file| {
hashed_file.failure catch |err| {
any_failures = true;
try eb.addRootErrorMessage(.{
.msg = try eb.printString("unable to hash '{s}': {s}", .{
hashed_file.fs_path, @errorName(err),
}),
});
};
hasher.update(&hashed_file.hash);
}
Here we see that all calculated hashes are being fed one by one into a new hasher. At the end of computeHash we return hasher.finalResult(), which we now understand how it was obtained.
Final multihash
Now that we have a SHA256 digest we can finallly go back to main.zig, where we call Package.Manifest.hexDigest(fetch.actual_hash). There we write multihash header to a buffer and after that, our combined digest follows.
Incidentally we see that it is no coincidence all hash headers are 1220. That's because Zig hardcodes SHA256 - 0x12, which has 32 byte digests - 0x20.
Summary
To summarise: final hash is a multihash header + SHA256 digest of SHA256 digests of files that are part of the package. Those digests are sorted by the file path and are calculated differently for normal files and symlinks.
Phew, this was longer than I intended it to be. It was also my first post on zig.news, so if someone gets to this point, please let me know if there are any issues with the content.
This whole investigation is actually a result of me trying to write a shelll script that outputs identical hashes to those of Zig. If you are interested you can read it here: https://gist.github.com/michalsieron/a07da4216d6c5e69b32f2993c61af1b7.
One thought I had after experimenting with this is that I am surprised Zig doesn't check whether all files listed in build.zig.zon are present. But that's probably a topic for another day.




Top comments (2)
I liked this article, at first I didn't underdstand why would someone care about the hashes specifically altho 1220 at the start does seems a bit off.
But still this was fun to read.
Also, why do you need this bash script?
I don't know why, but I didn't get email notification about this comment?
To answer your question: I wanted to understand how does Zig handle downloading and verifying dependencies. This is important in multi-stage build environments like Yocto. There, only big build tool Bitbake is supposed to access internet and small build tool like Zig, Meson, CMake or Bazel must be able to use what's been downloaded for them.
I assumed that to support Zig in Yocto, I would have to reimplement the logic for file removal on Bitbake side. It could be a special task after tarball is extracted. As Bitbake supports bash and python, it could have been either of them, but I like to write shell scripts. Thankfully, the analysis showed there should be no actual need for that, as Zig should be able to handle file removal on its own.
Maybe one day I will actually get to it and make some proof of concept Zig compilation inside Bitbake and write about it as well.